
TL;DR
If you’re looking for the next big thing in AI; this isn’t it.
Instead, this is me finding and starting to fill my knowledge gaps in machine learning after having been away from it for far too long.
The data set is location data from my Auto-pilot project, and the task is to:
- Identify bad location data (I actually wrote a cool algorithm for this already.)
- Predict what the bad data should have been.
But the journey is so much more interesting than that. This is not a how-to; there are lots of those already. Instead the story of the journey, the things I learnt along the way, and what to think about to make it better, are much more interesting.
Table of contents
- TL;DR
- Table of contents
- I’ve been here before?
- What am I trying to achieve now?
- Diving into the details of goal 2 (prediction)
- How this would be used
- The plumming of the prediction model
- What I’d do to imporove the accuracy
- The quality of this project
- Commentary on available material
- Credits and recommended reading/watching
I’ve been here before?

Above: Me using my very primitive AI implementation in the mid 90s.
In the mid 90s, I wrote a very primitive AI chat implementation. It was nothing compared to what we have now, but it turned some heads at the time, and got me first place in the Senior Technology section of the science fair.
In fact, It was so basic, that I hesitated to put it here. But I remembered what I planned to do next if I continued, and how similar that is to where we are now, and wish that I’d kept with it. Instead I moved on to writing algorithms for generating 3D graphics without using the GPU or external libraries.
What am I trying to achieve now?
While working on the Auto-pilot project, inaccurate location data was a big problem when trying to precisely navigate the plane. While there was likely an option to turn off this inaccuracy in the flight simulator, it is something that I’d have to deal with in the real world, so I wanted to find a way to deal with it.
I created an algorithm that is able to reliably pick out when the data is wrong:
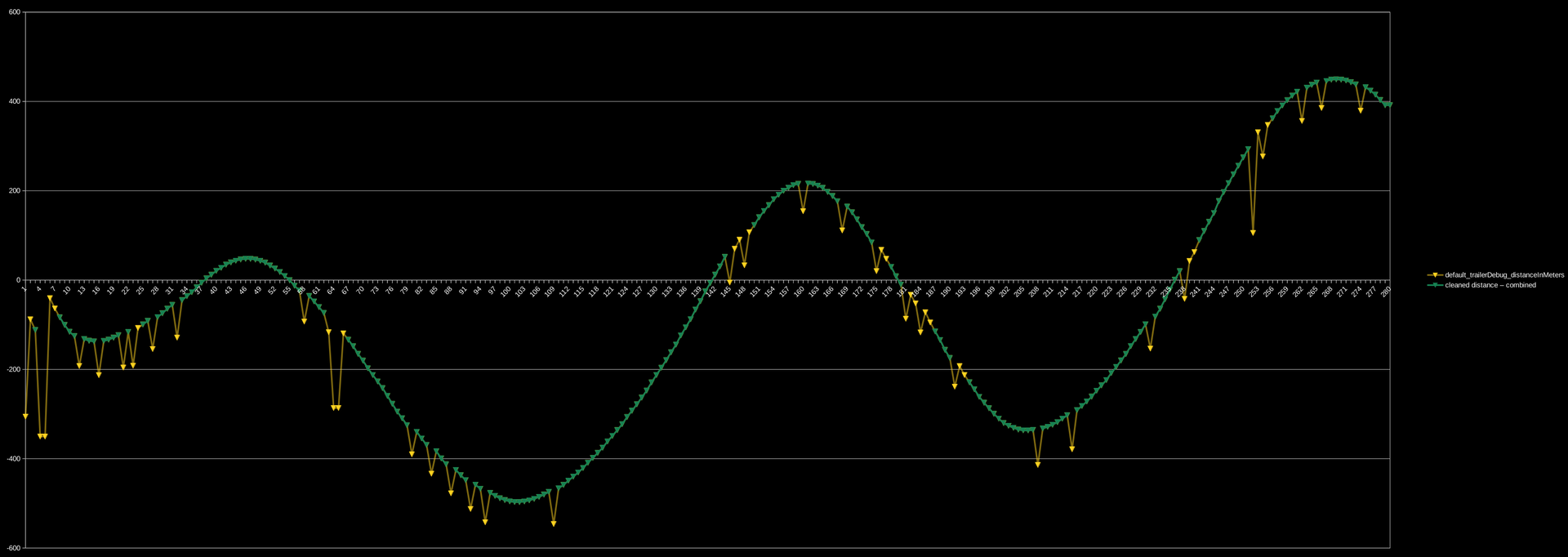
Above: A graph showing the error being detected and excluded.
- Yellow: Original raw data (distance from the line that we are trying to follow).
- Green: Data that has been identified as correct.
It’s important to note that any idea you can come up with for how to quickly filter out the bad points is almost certainly wrong. It might work in one case, and then break 10 legitimate ones. Seriously, it’s not as obvious as it looks.
Assumptions
- Data
- Sample rate: ~1Hz (Around 1 sample per second.)
- Angles are measured in radians.
- Physics
- Commercial planes are heavy, and don’t make large changes in direction quickly.
- Noise
- Satellites coming and going create large, sudden changes to the data.
- Sometimes a single data point is way off. I think that this is a bug in the interface that I’m using to interact with the flight simulator. Regardless, it’s an error that I need to account for.
- A stationary plane can have minor noise that is larger than it’s legitimate movement. A moving plane doesn’t, so the signal to noise ratio is very favourable for this type of noise. I used a cut-off of 10 knots when filtering the data.
Goal 1/2: Detection
I wrote the error detection algorithm for the Auto Pilot in Achel, and for this project, I wanted to brush up my Python. The detection goal was the less interesting of the two goals. So rather than take the time to port the algorithm to Python, I simply used a couple of if conditions to tag the training data. This is no where near as good, but gave me a quick way to play with the concepts and move on.
The way I implemented this model is an interesting story in itself, but is probably better as a separate post in the future.
It didn’t take very long to get the model to be very accurate at replicating those two if conditions:
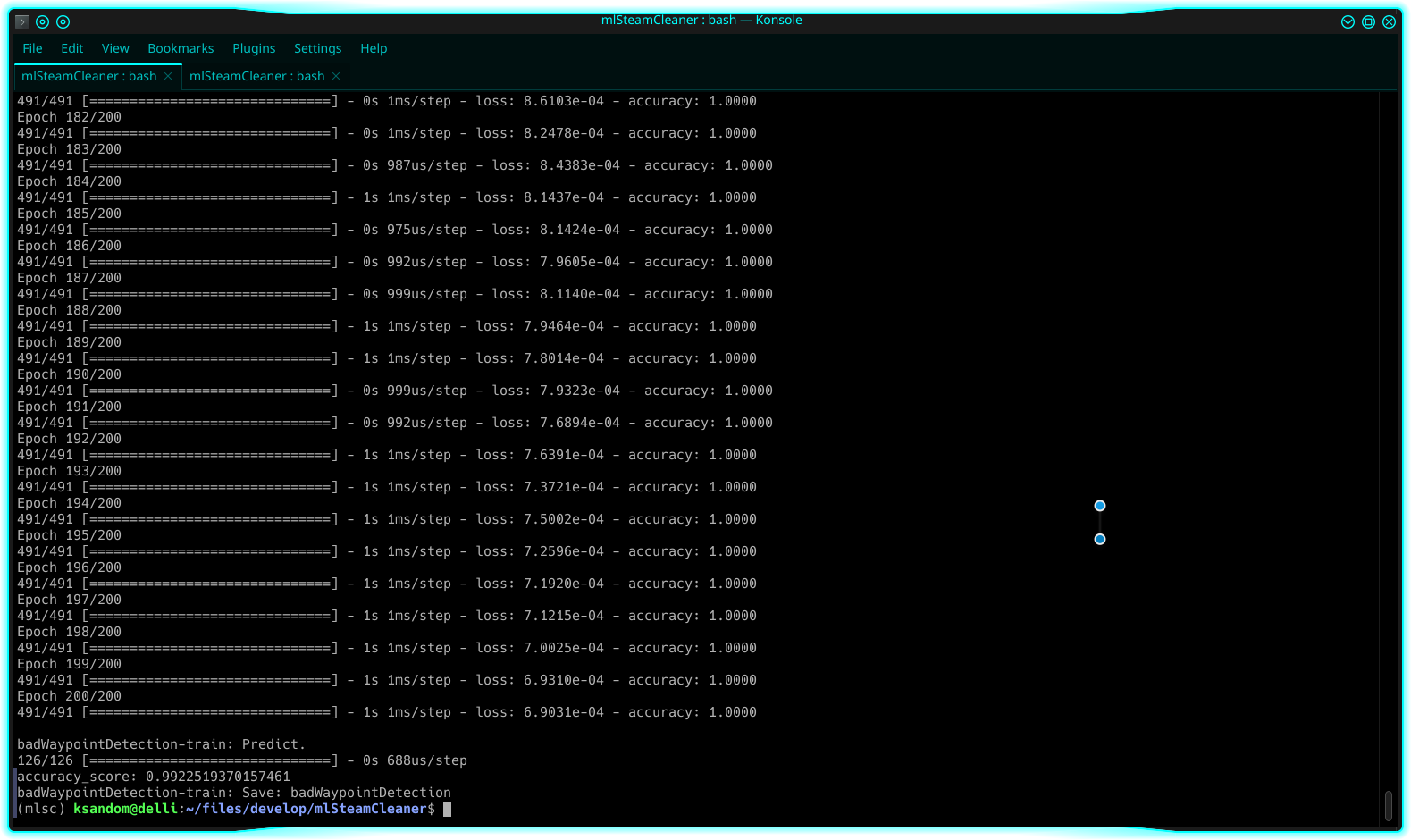
Above: 99.2% accurate at replicating the two if conditions.
Sweet. Moving on.
Goal 2/2: Prediction
Predict what it should be.
… Goodness, that sentence is very short compared to the amount of work. Easily 80% of that time was spent on making sure that the data was clean enough to train the model well. In hind sight, I might have benefited from porting my error detection algorithm. Perhaps I’ll do that soon.
The short story is that I got it to work:
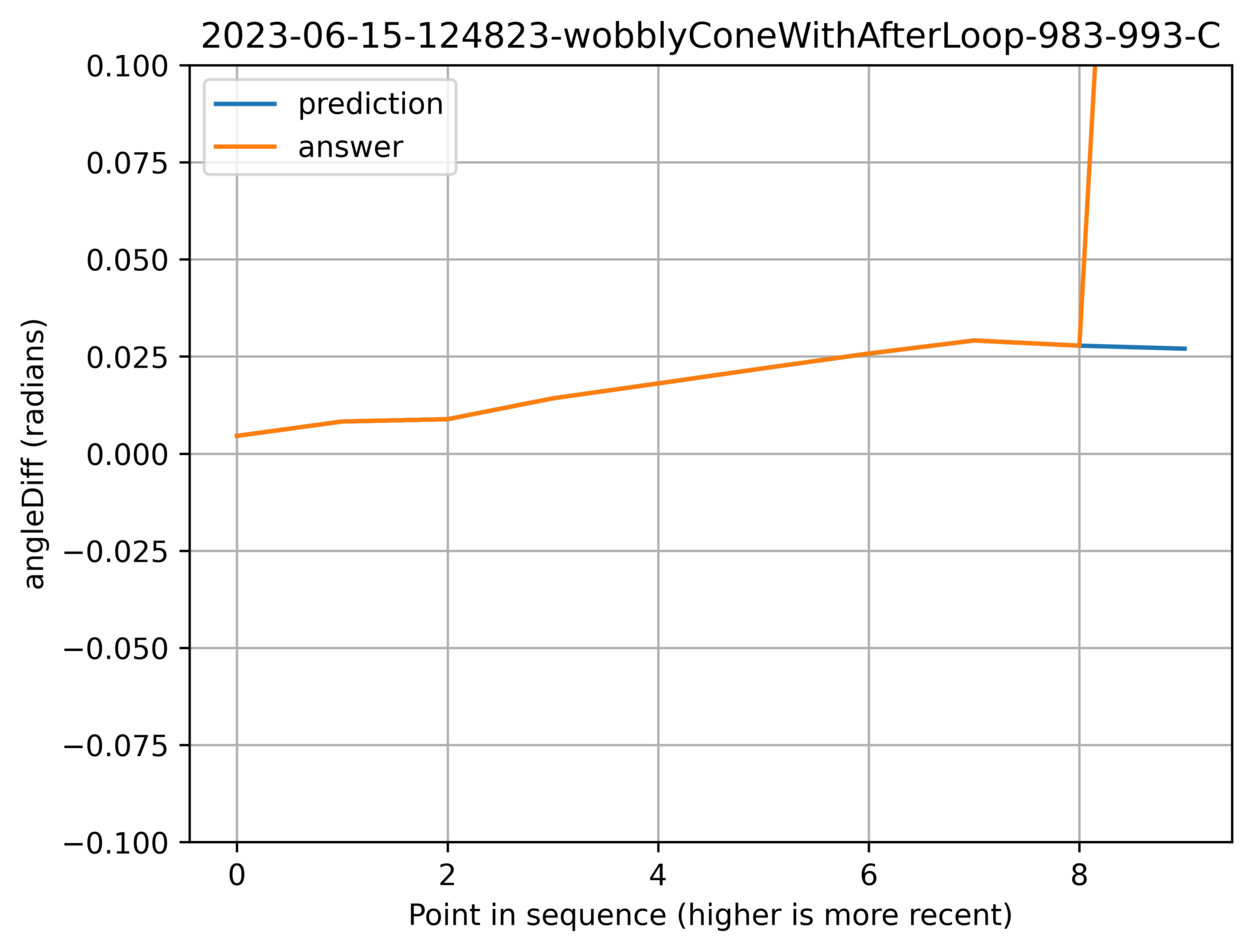
Above: The model is predicting a likely next point.
- Orange is the raw data that came from the flight simulator.
- Blue is the prediction of what the value should be.
- angleDiff is the difference in the line angle between the current point and the previous one. And can be thought of as the angular velocity.
- angleDiffDiff (referenced later) is the difference of angleDiff between the current point and the previouis one. And can be thought of as the angular acceleration.
- Data sets:
- -A: Training data.
- -B: Test data.
- -C: Rejected data (usually because it has bad data points in it.)
- The title identifies the flight, and which rows from that flight. In this case from 983 until 993.
Specifically, the last orange point in this graph is way off the scale. The last blue point is the model’s guess of what that value should be without knowing what the original value was.
Diving into the details of goal 2 (prediction)
Let’s start by looking at some graphs. I have over 49,000 of them. That wouldn’t make a very interesting blog post. But we can look at some interesting ones.
Graphs
Corrections
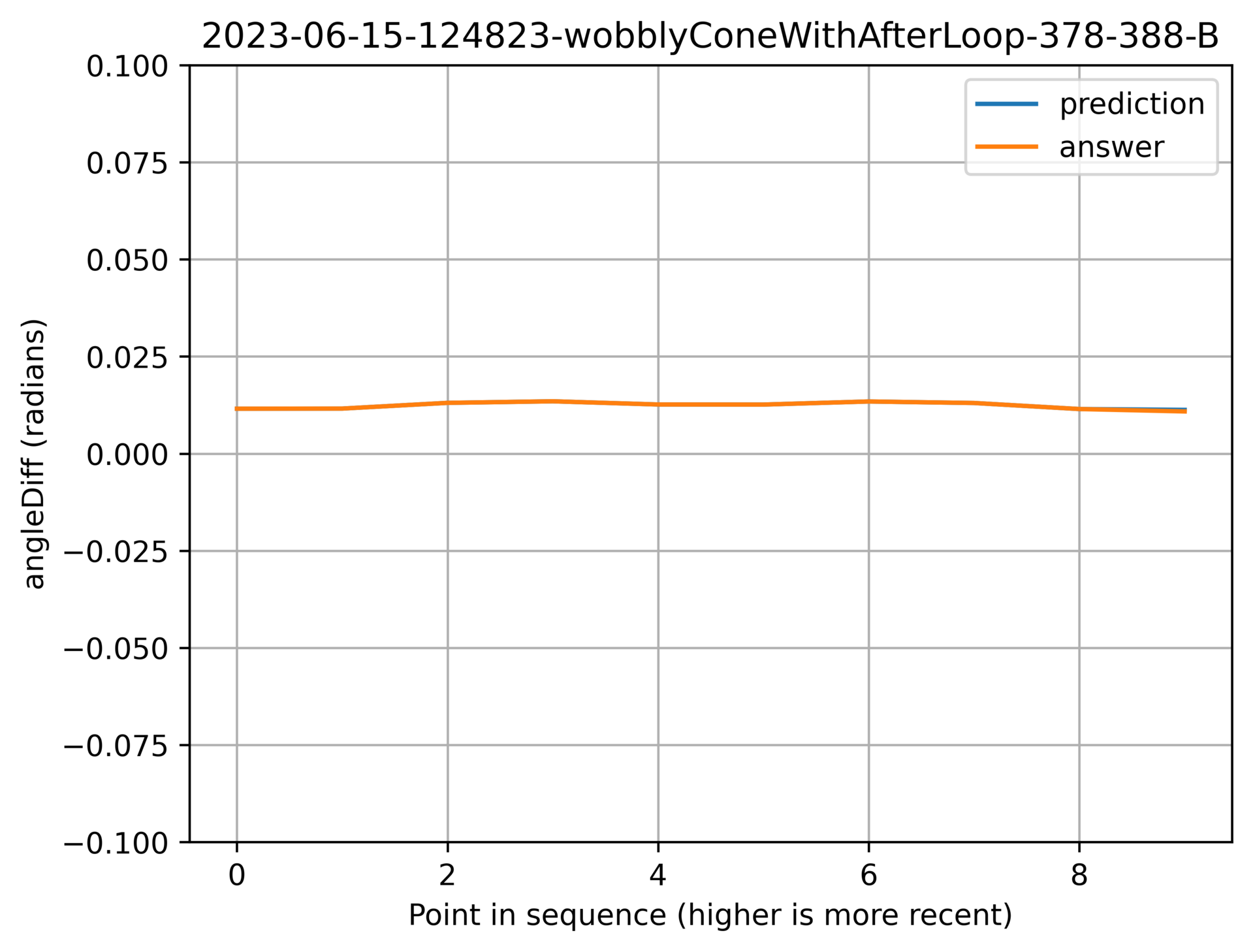
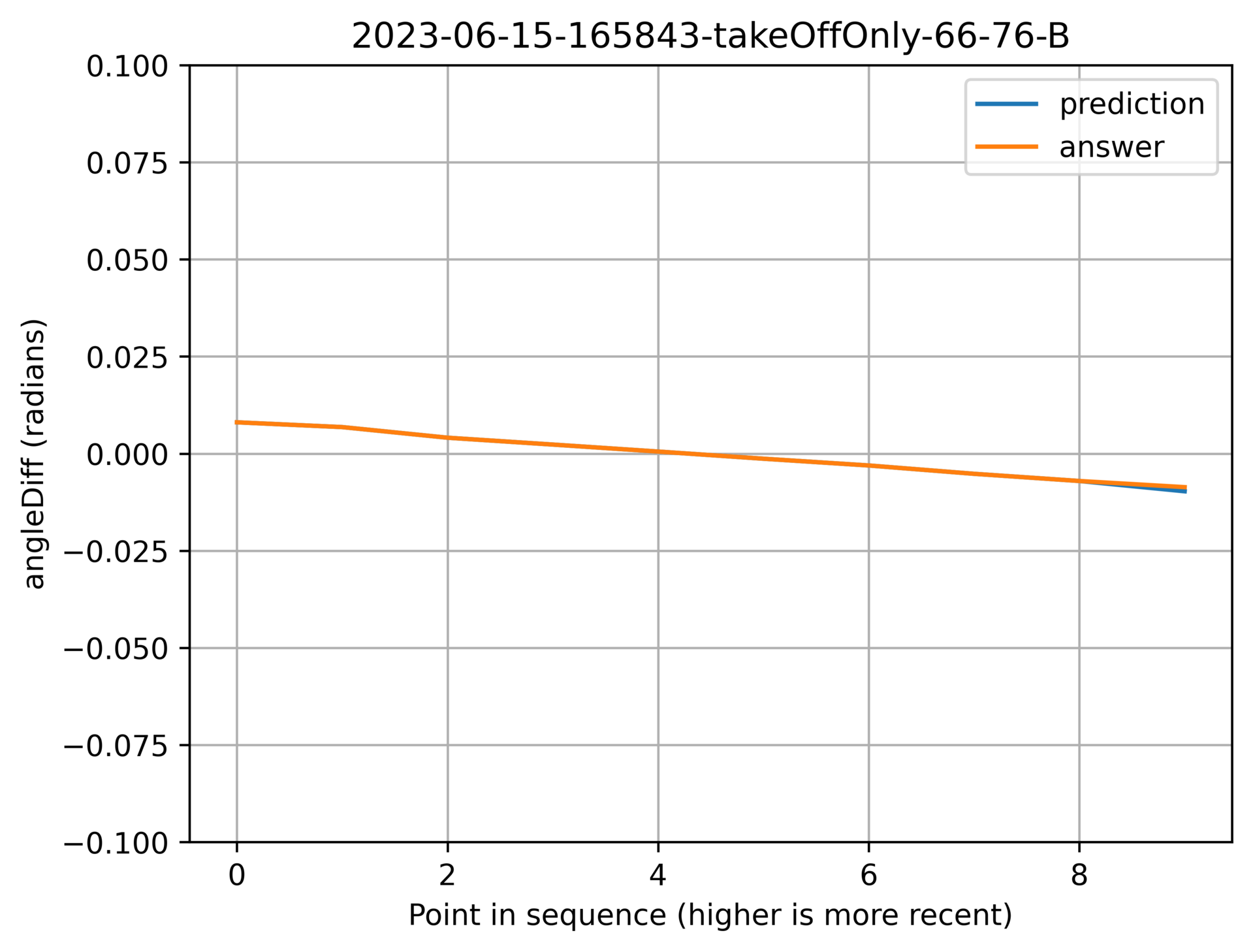
Here are some nice examples to show off it working well:
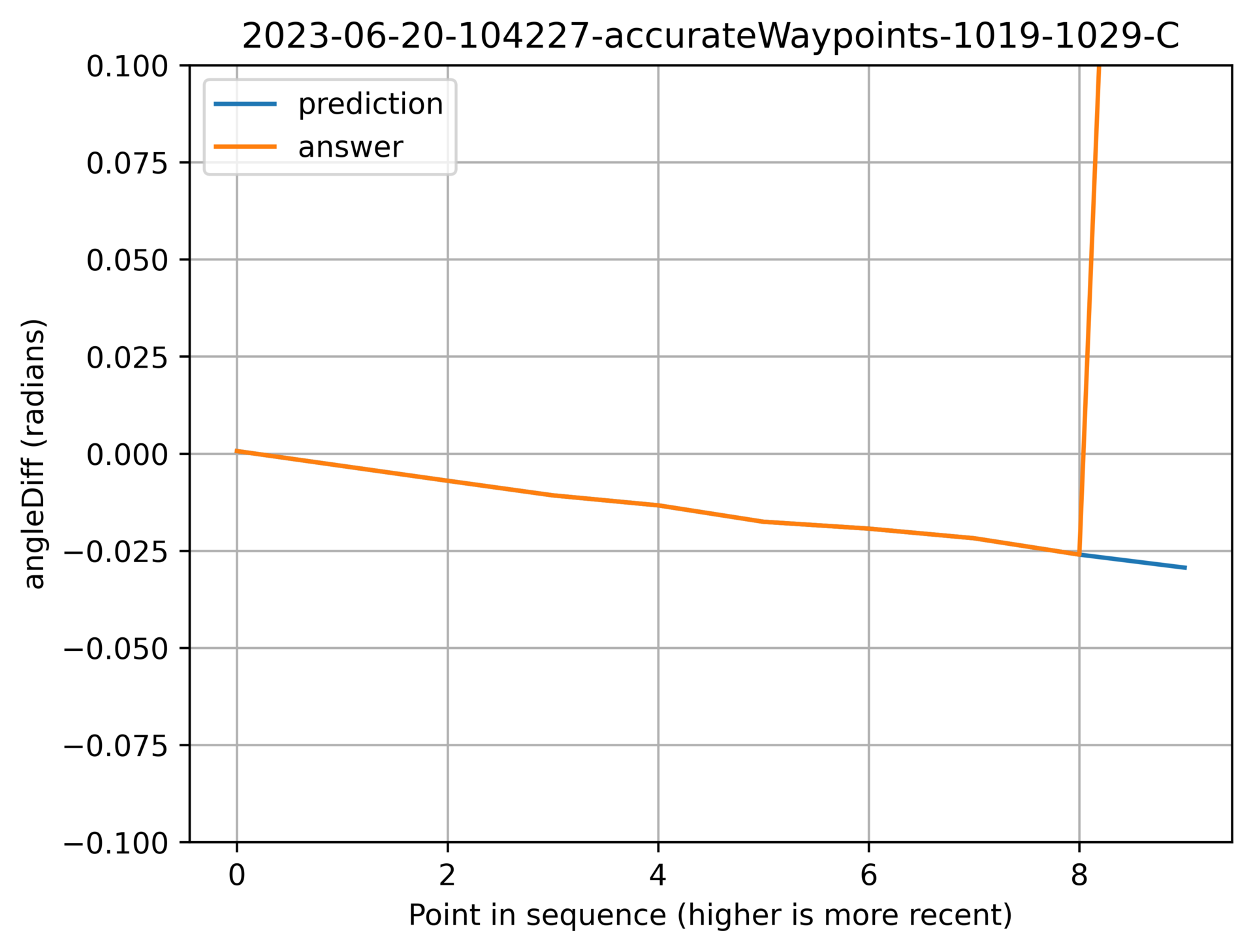
Above: Correctly picking up on the slope.
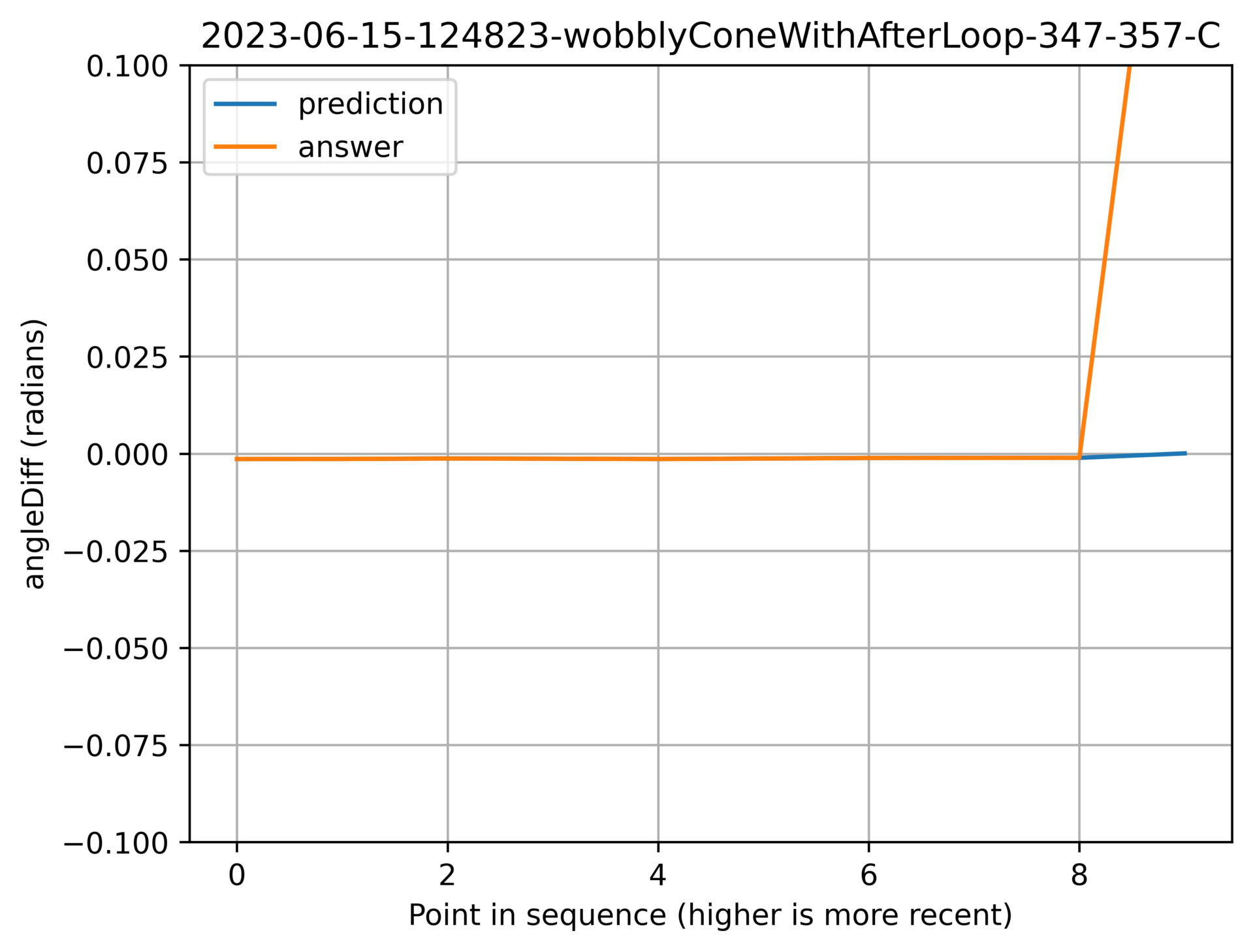
Above: Correctly being really boring.
Above: Picking up on the oscillation.
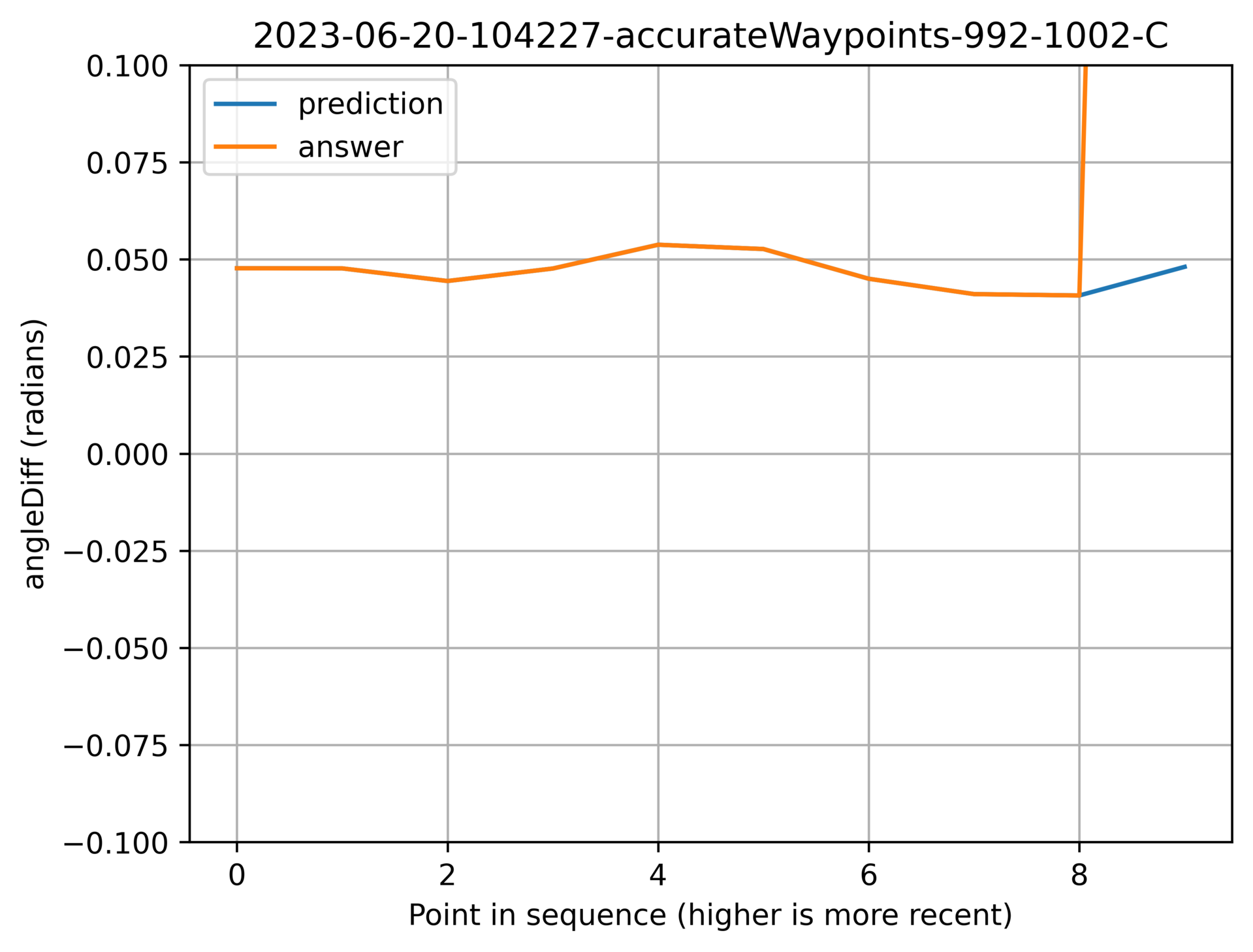
Successfully doing nothing
Here are a couple of graphs of the model being bang-on the actual value. I have looooots of these.
Above: The two lines almost exactly overlapping.
Above: A stronger slope while the lines remain tightly overlapping.
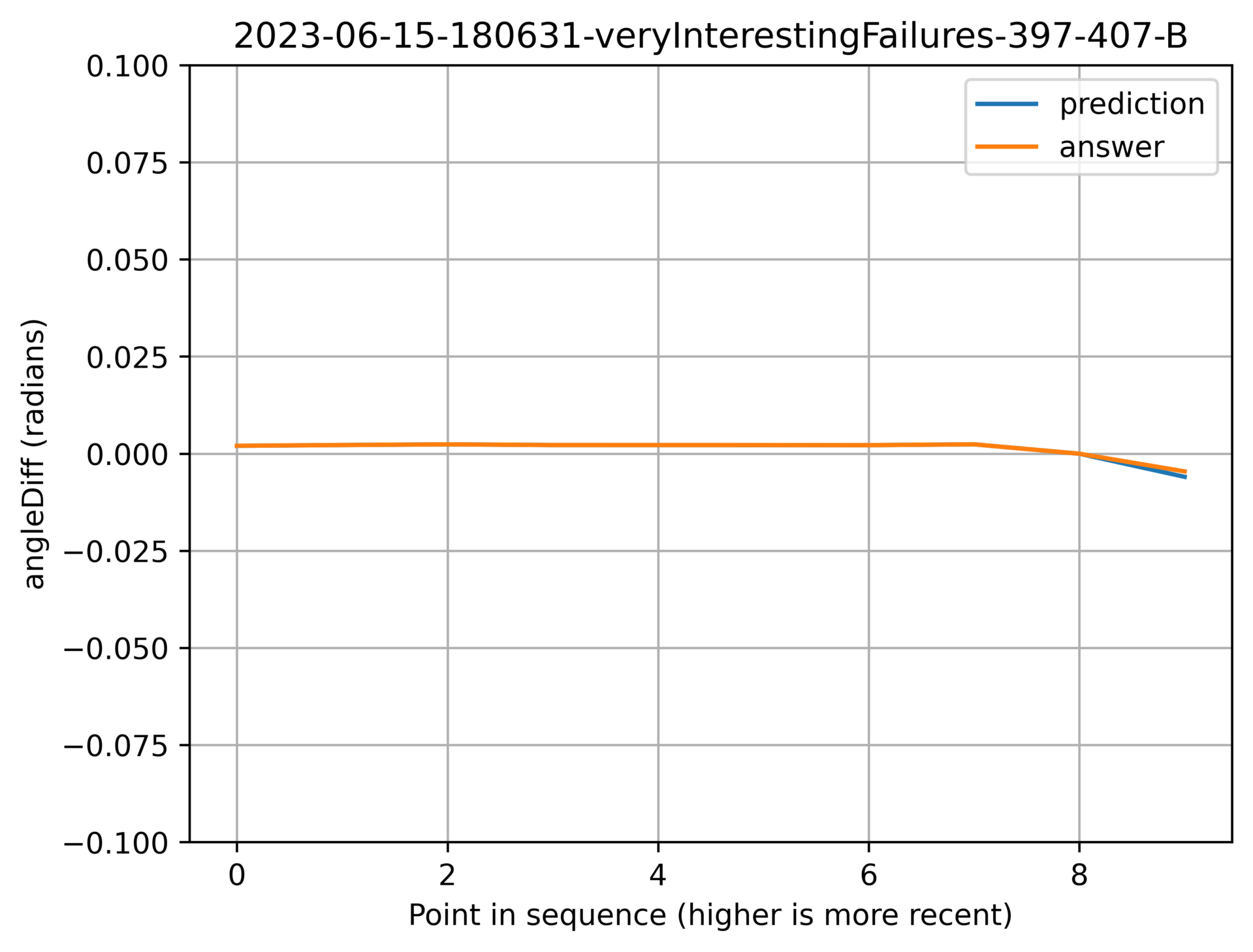
Above: The lines staying tightly overlapping while changing direction at short notice.
I find this last one really interesting. I doubt that I would have guessed it that accurately more often than not.
A human would probably do this too
Here are a couple of predictions that were probably wrong, but a human would probably have done the same thing.
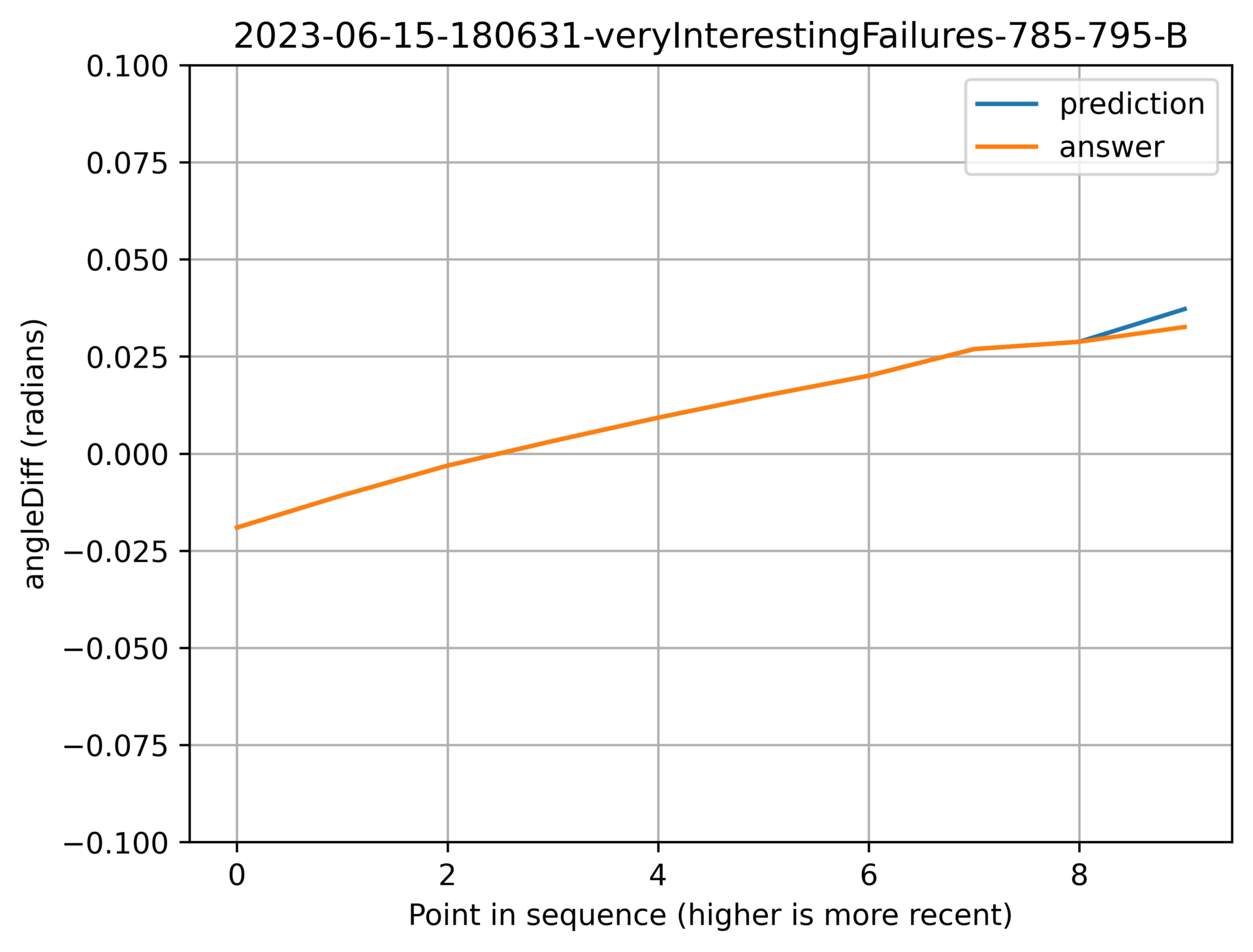
Above: The model observed the gentle curve. Instead the reality changed.
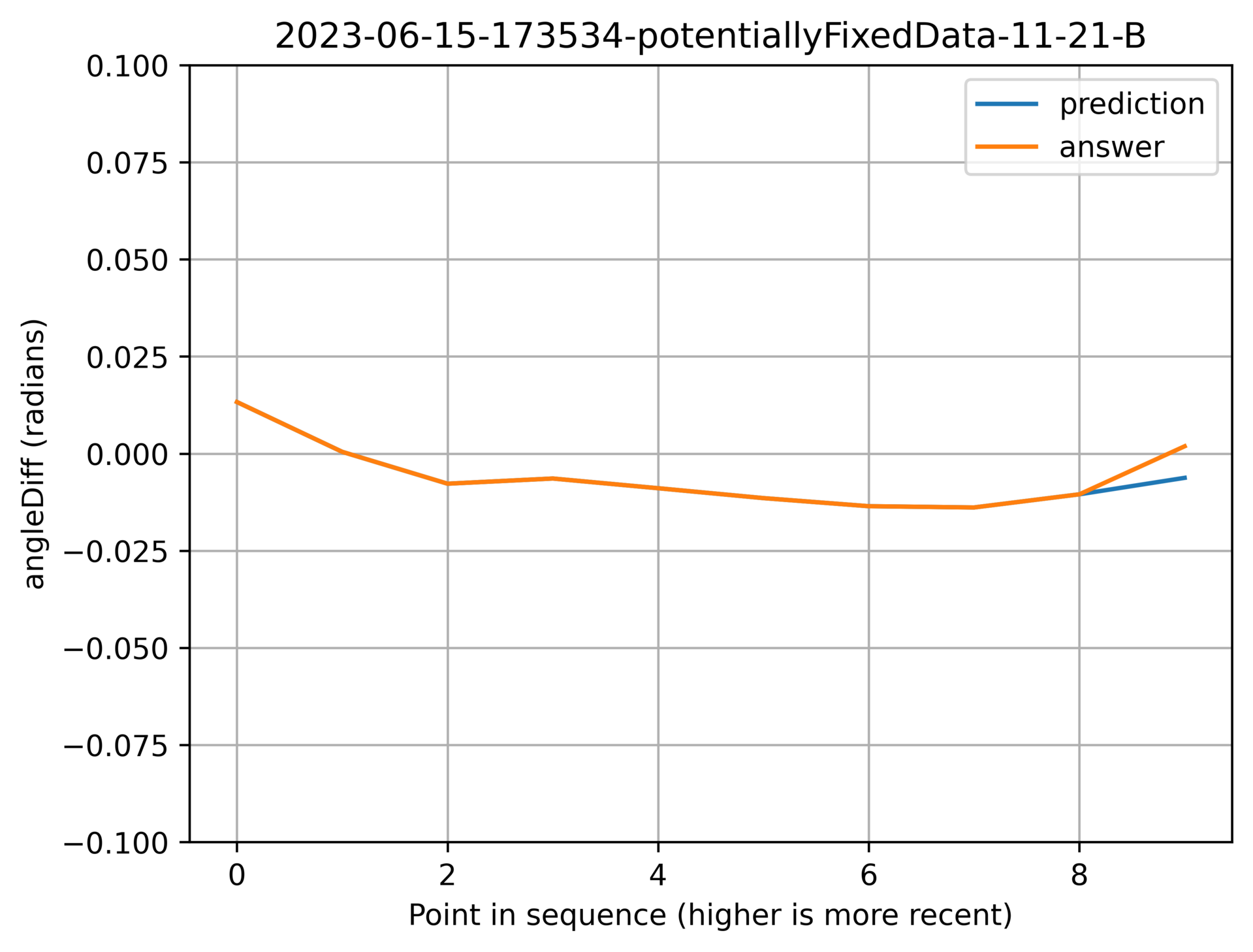
Above: Based on the rest of the line, The previous point could have been a wobble, or a change in trend.
Garbage in, garbage out
When bad data gets through to the input of the model, the output will be very bad:
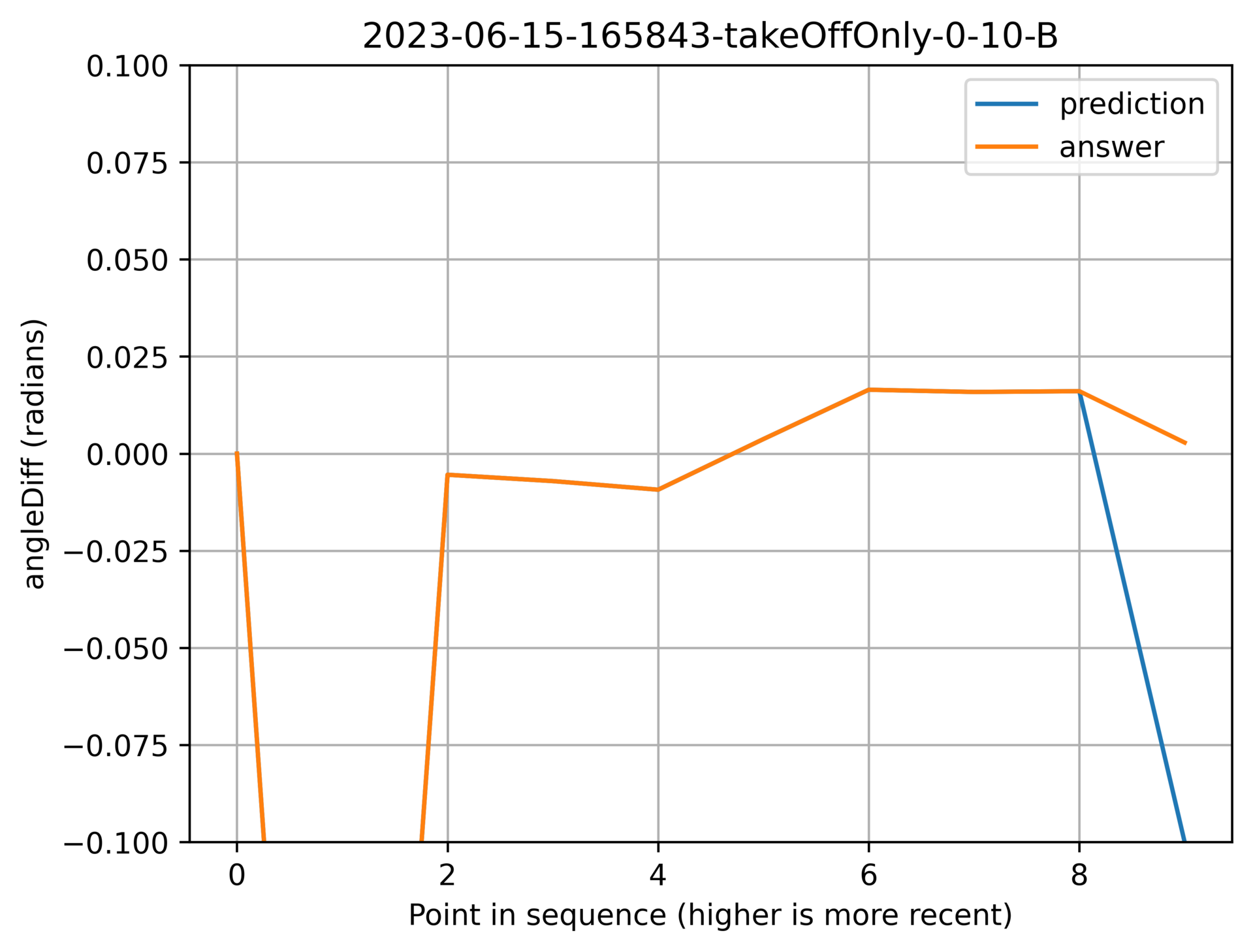
Above: A bad data point that got through my filtering caused a bad result.
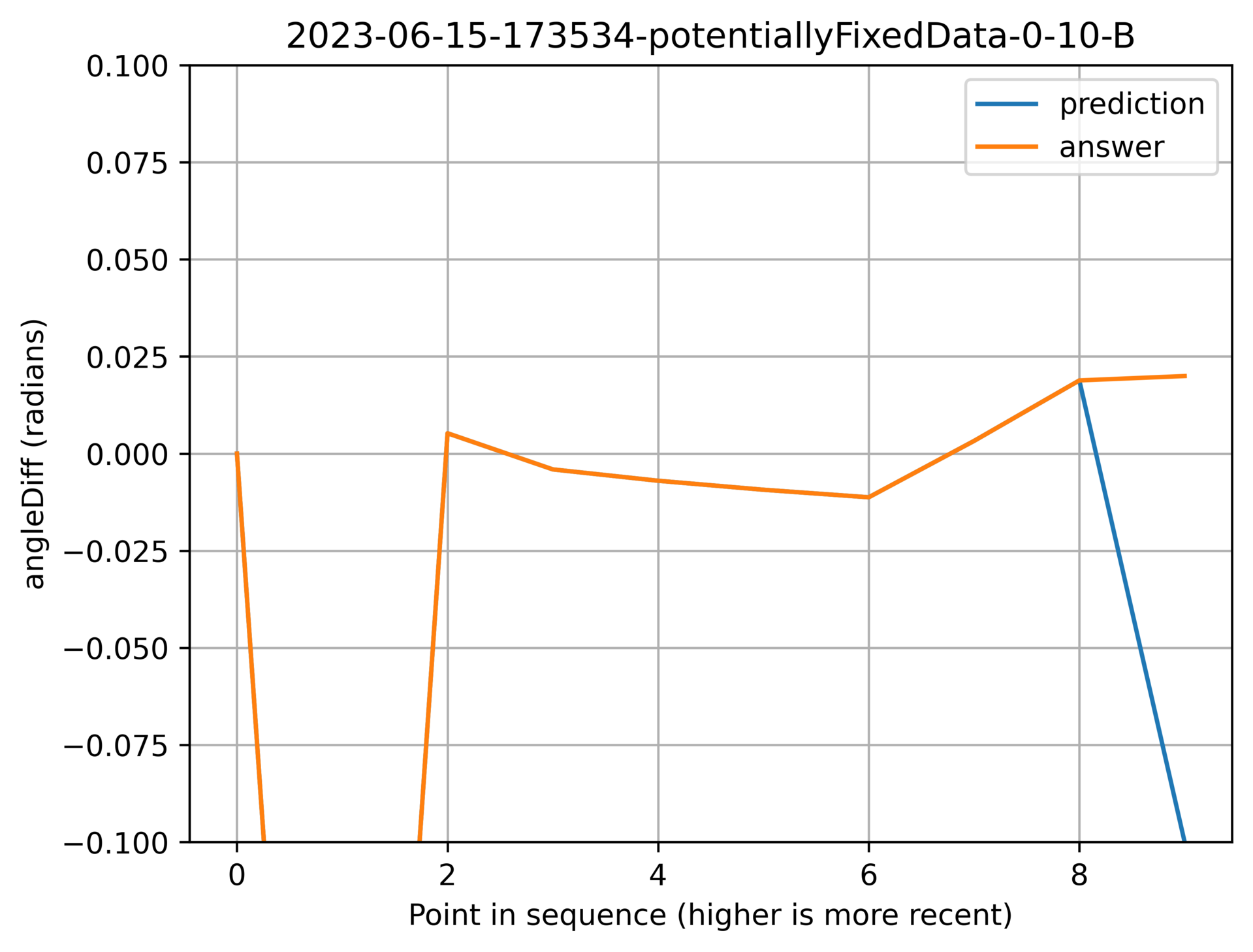
Above: Another bad data point that got through, wrecking havock.
So, how good are the predictions, really?
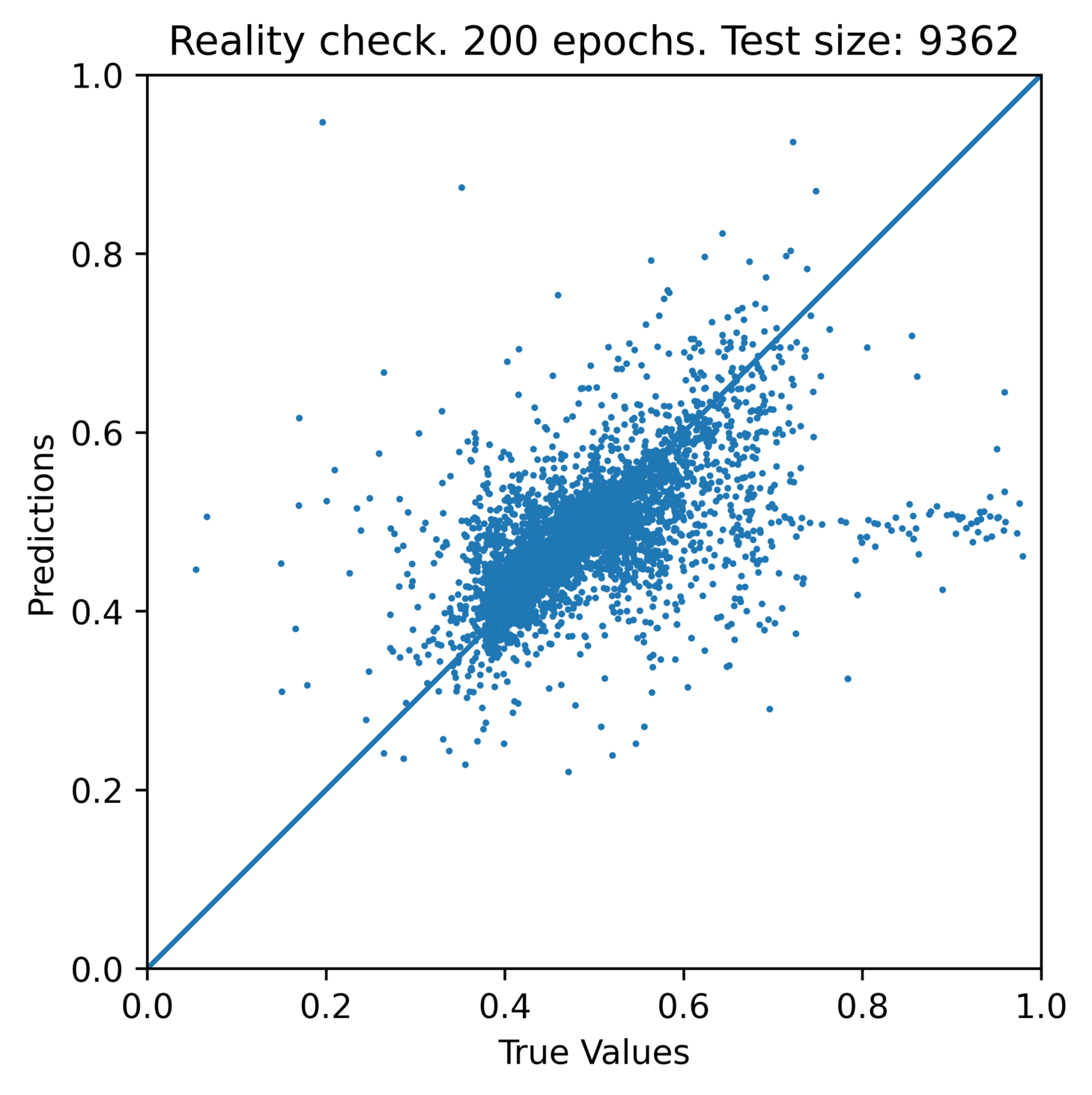
Above: Scatter plot of predictions vs what the raw data.
NOTE: that the scale on this plot is normalised between 0 and 1, and is not to the same scale as the other graphs (radians).
If the model was perfect, all points would be on the line.
The raw data is along the x (horizontal) axis, and the prediction is on the y (vertical) axis.
You can see a definite trend close to the line. But there’s still a lot of error in there that I’d like to reduce. There are several things that I could do to improve this, but the first thing I’d do is filter out the bad data like from Garbage in, garbage out in both the training, and the test data. Specifically, I’m talking about removing the error in the history, but also training on bad answers will also throw off predictions.
It’s important to recognise that the incorrect results that the model successfully corrected will show up as error on this plot. I haven’t thought of a good solution to this yet other than to simply identify those, and exclude the bad raw data from the plot via other means, because I don’t have a good way to measure what the value should have been independently of the model. Even if I exclude them from the plot, they are the most interesting data points to test the model.
While it’s easy to see that removing the bad data from the training data will improve the predictions. The test data will also influence the quality of the testing predictions since the model is essentially a whole heap of weights, so extreme input values can wildly affect the final output.
Having said that, it may be possible to train the model to be resistant to this. However my inclination would be to place the protections earlier on. Either as traditional code, or having a another model (like the detection one above) to identify bad data before the problem becomes compounded.
So let’s take a look at instances where the model made things worse:
When good models attack
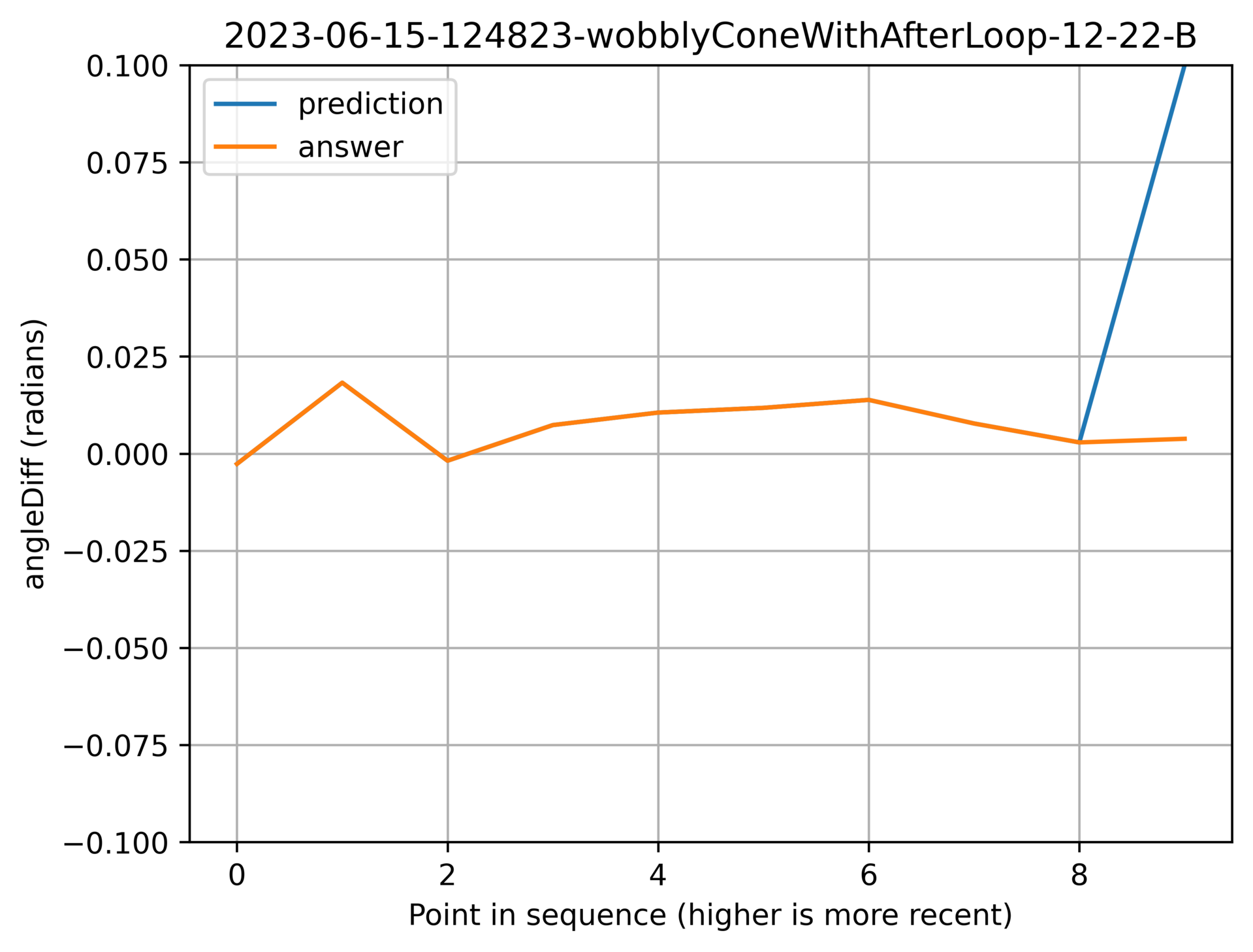
Above: A small spike early in the history caused erratic output.
Above: Random spasm.
While it’s easy to guess the cause of the first one, the second graph puzzles me a bit more. My best guess is the amount of error that is still in my training data.
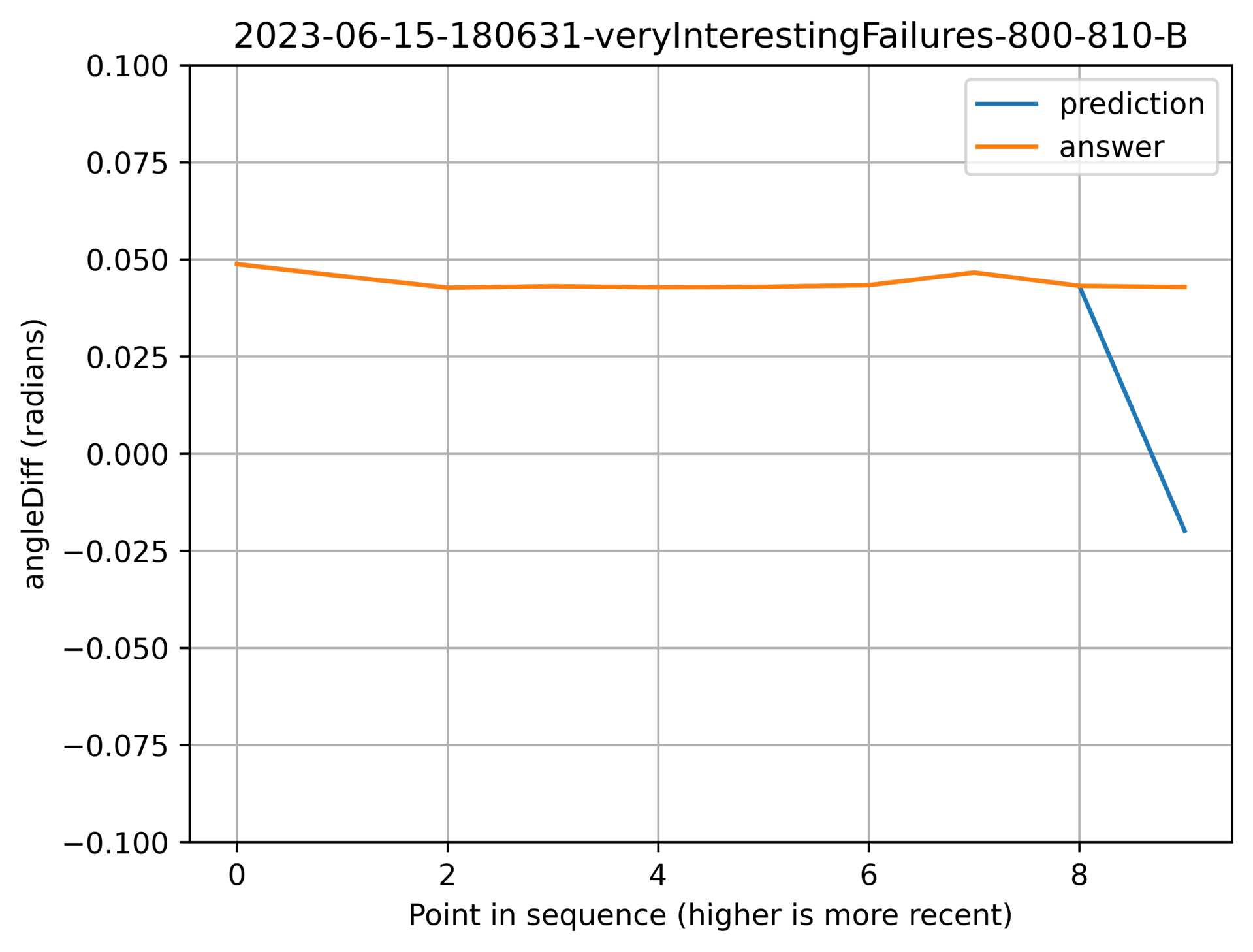
In my skimming through the graphs, results like the two above breakages seem very rare. What’s more common are graphs like this:
Above: A small deviation.
Above: A larger deviation.
I’m not too concerned about the small deviation, and I haven’t solidified my opinion of the larger one. On one hand, maybe point 4 was an error that should have been detected. Or maybe it’s reasonable to receive data like that from time to time, and the model should cope with it without giving a wildly inaccurate prediction.
So this is probably a good place to jump into how I’d use this model in the bigger picture:
How this would be used
While the model is doing an excellent job at fixing the broken data. There are enough instances of it breaking good data that I’d want to add an extra step into how it’s applied:
Identify the bad data, either via an algorithm like the one I developed for my Auto-pilot project, or improve and use Goal 1 (recognition), to identify data points that need to be corrected. Only if the data point has been identified as bad, would I then run the recent history through the prediction model to correct the data.
With the combination of these two things, it should give a very stable result.
The plumming of the prediction model
When looking at other peoples’ tools like ChatGPT, Stable Diffusion, it’s very easy to wave your hand around and talk about the general principles that they are built on. Meanwhile there are likely challenges and solutions would not be obvious until you need to think it through all the way.
The most interesting for this project is:
- What data is sent to the model?
- What data is returned from the model?
Normalisation
All data in this project is normalised between 0 and 1 before going in to the model. and de-normalised when coming out of the model.
Input vs Answer
- Input: Last 9 angleDiffDiff (angular acceleration) values (the 10th is used for training and testing).
- Answer: angleDiff (angular velocity).
This may not be intuitive at first. So let’s work through it.
We take a series of longitudes and latitudes. These are absolute positions and, for the purposes of this use case, will never have a repeatable relationship between them that makes sense for learning. So we need to convert them into into something relative.
I’ve gone with an angle, and a distance between each pair of points.
That distance looks pretty yummy, doesn’t it? It’s very easy to work with and think about. The problem with it is that an error could be in any direction. So there are lots of likely bad points that would escape detection.
So we need to focus on the angle. But it’s an absolute angle. So let’s diff it from the previous angle to get the angleDiff, which is how much the angle changed since the last point. This means that we don’t have this information for the first data point, but we can calculate it for all the subsequent data points. And then we can calculate angleDiffDiff the same way.
Important: Each layer of diff is calculated using the current data point against the previous one. While not mathematically perfect, it gives us highly-current data that we can act on.
The characteristics of angle, angleDiff, and angleDiffDiff are interesting to compare.
- angle is absolute and doesn’t make a lot of sense to learn from.
- angleDiff gives us a rate of change and is very easy to work with. But has a smaller version of the same problem that angle has in that it’s not very repeatable, so is hard to learn from.
- angleDiffDiff only bedcomes non-0 when something is changing. This is great for making changes of trend stick out, and is therefore excellent for teaching trends.
Therefore we want to get an angleDiff back, but learn from angleDiffDiff. When plotting the graphs, I took the angleDiff values from the history, except for the final point that the model was predicting.
Applying the answer
So we have an angleDiff, and we have the angle from the previously known good point, and we have that yummy distance.
So we can apply the angleDiff to the previous angle, and then use the yummy distance to calculate the exact coordinates.
What I’d do to imporove the accuracy
- Find and remove as much bad data from the training data as possible. There’s definitely more that I haven’t successfully filtered yet.
- Don’t use bad data as a source of truth when measuring success.
- But keep it for manual testing, because it’s excellent for visualising how well the model is working.
The quality of this project
This project has been a prototype test-bed for me to find the gaps in my knowledge of both Machine Learning, and Python, and the code-quality shows. It’s fixable, but not within the time I have available right now.
It should not be considered a showcase of excellent code.
However, if you’d like to play with it yourself, you can do so at ksandom/mlSteamCleaner on GitHub.
Commentary on available material
I had some pretty big gaps in my knowledge around where things are currently at with Machine Learning. So was looking for material to jump start me.
pyTorch
I started my research looking for pyTorch material, because I had heard of it several times around tools like Stable Diffusion. I spent a stupid amount of time searching. Yet all of the tutorial videos or documentation that I found while researching this landed in exactly 1 of 2 possible categories:
- ~70%: Image recognition tutorials.
- ~30%: Incredibly slow/wordy, grain-of-sand on the beach level of detail, that I simply wasn’t ready for.
Image recognition is really cool, but it’s very different to what I was trying to do. I suspect that material on what I was trying to do does exist, but is buried by the sheer volume of what people are excited about at the moment.
TensorFlow
Since I wasn’t getting anywhere with pyTorch, I started looking for TensorFlow material, and found relevant material on the first shot. Every time I looked for something, I found it.
My understanding is that for a lot of tasks (especially one as simple as what I was trying to do), both platforms are viable. Yet, I really didn’t get that impression from the available material. If you’re making ML tutorials, and looking for a place to make your mark; there’s a gap here.
Credits and recommended reading/watching
There’s lots of great material available online. I want to point out two: