
While trying to automate a landing, I accidentally automated Javelining the plane into the ground. I actually got past this, and had plenty of next steps to pursue. But for personal reasons, I was absolutely out of time.
This post is a reflection of how the project went, what I was trying to achieve, and what I’d do differently next time/later. In a future post, I’ll dive into some of the awesome stuff that came out of it that are going to influence future projects that I do.
Table of contents
What went wrong
Time vs the size/scope of the project.
It’s really that simple. While I focussed on the finer details in the video, the most important factor is that I was trying to do too much in the time available. There were shortcuts that I could have taken to speed it up, but they would have directly contradicted what I was trying to achieve with the project.
What was I trying to achieve with the project
The early years
When I began the autopilot project, I had two goals:
- Push Achel forwards. (Achel is my language for robotics.)
- Be the flagship project for demonstrating what is possilbe with Achel, and the best practices for doing them.
While it sounds logical at first; in hindsight, these two goals are opposed to each other because pushing the language forwards involves discovering new requirements that need to break previous assumptions. Or maybe there are multiple possible solutions. The best practices change as new ways of solving problems become possible. These changes create the need for cascading changes. Sometimes those are essential for the project to work. Other times they are simply cosmetic, or for consistency. All of this adds inertia against getting things done.
By contrast a Flagship project requires that everything is neat, and tidy. That documentation is exactly up-to-date with how the code works right now. That the latest techniques are used for each piece of code.
For a set of projects of this size in the business setting; you overcome this contradiction with brute force (multiple people working on the project), and with agreed unified approaches to everything. When you’re one person working on it in scraps of time during train journeys; you choose (whether you do it consciously or not) whether you’re going for flagship, or getting things done.
The catch, is that going the messy route, gets things done. But it creates technical debt that can paralyse a team. It can also paralyse a single person when you can’t dedicate large-enough blocks of time.
This time around
The moment has long-since passed for me to present anything new and innovative with these projects. Watching other people over the years slowly implement ideas I had years earlier has been one of the most heartbreaking things about these projects. When ever I’ve had a bad day; these are the projects that I’ve been wishing I was working on.
So this time around, my goal was simply to finish some of the things that I had been wanting to work on for all of this time. In particular:
- Clean take off.
- Stay on the runway until rotate.
- Bank away at a safe altitude.
- Implement the icecream. - A way of preparing for the final approach.
- Land on the runway.
- There were a couple of bonus goals, but I’ll keep those to myself for now since I’ll probably do those in the near future.
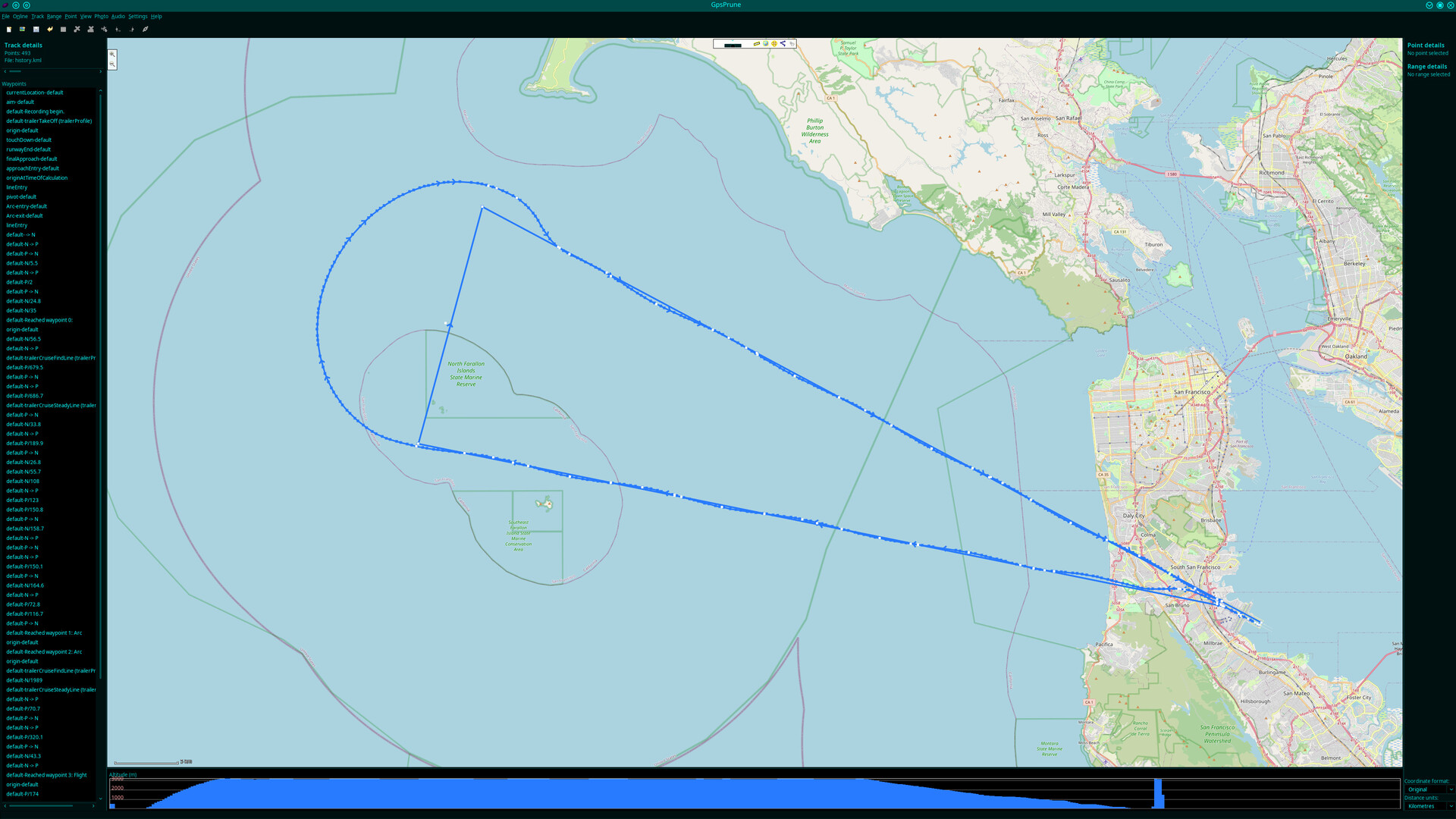
Above: A screenshot of the ice cream working well.
Common goal
Both when I started these projects, and now, I wanted to figure out how to do each thing, and then see if it works the same, better, or worse than established methods. In many cases, I could simply look them up on Wikipedia, or stack overflow. But if I do that, I’m robbing myself of the deep understanding that comes with figuring it out for yourself. However, following-up with sources like that afterwards can take that understanding to the next level.
What went well
- Take-off. I actually got this for free as my control logic improved.
- Adding the ability to switch between different config profiles for different phases of flight and goals. - This made it immensely easier to tune the algorithms.
- Control logic:
- Tuning - How to iterate faster through time-consuming testing.
- The ability to quickly add new algorithms, and test them against the other algorithms. This was a structural and automation change.
- Data cleaning. This is perhaps the thing I’m most excited about, and will definitely make it into some of my other projects.
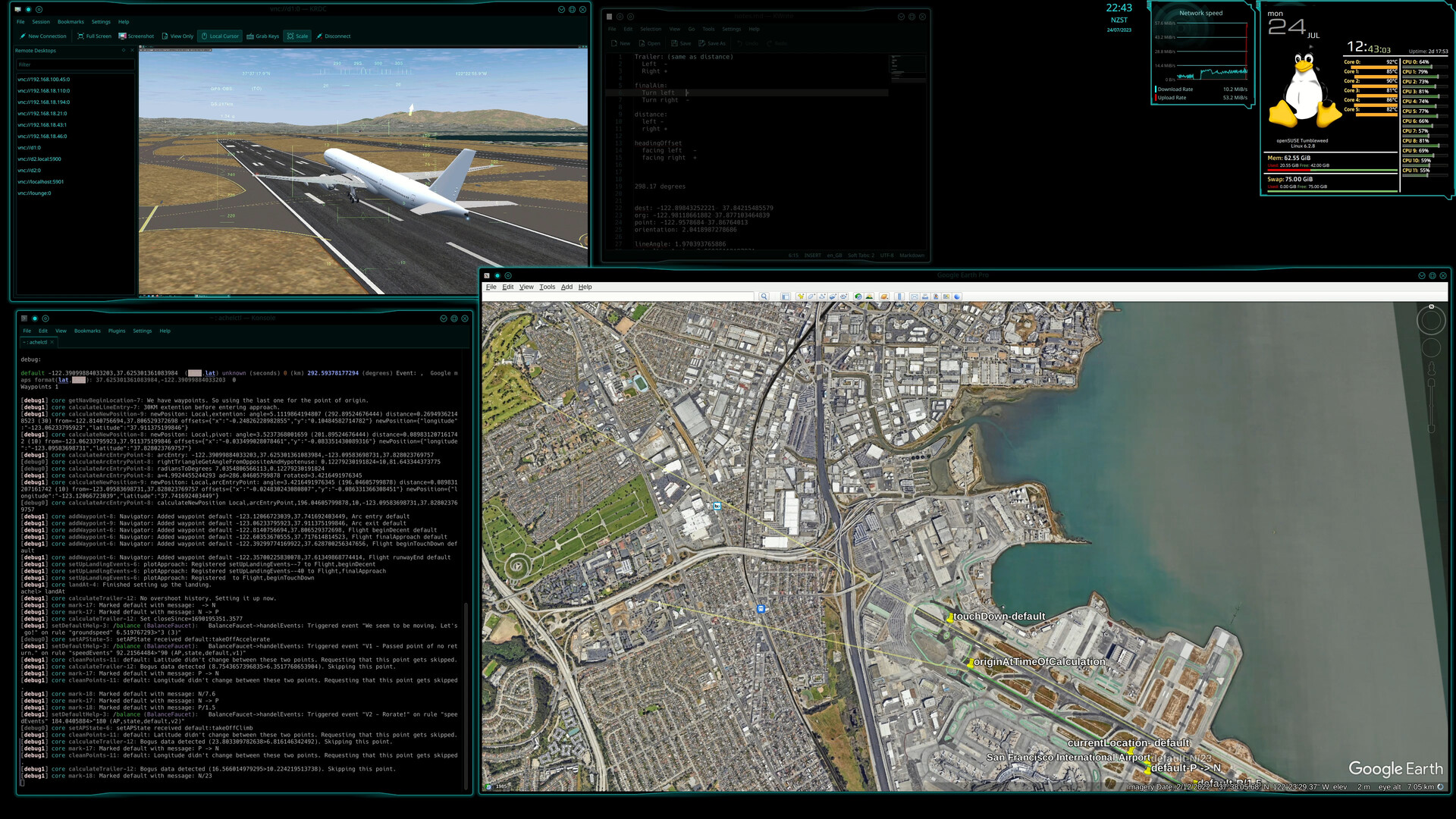
Above: A screenshot of the plane takig off while cleanly staying on the runway.
What I’d do differently next time
- Implement specific already-air-born control-logic tests for faster iterating.
- I did this for following an arc, and it made all of the difference to being able to implement the arc in a reasonable timeframe.
- Implement data cleaning WAY sooner. This made so much difference once I did it, and would have saved a lot of trouble.
- Implement using the official API much sooner. - Let’s talk about this one a little more:
The official flight simulator API vs the debug API
When I began the autopilot (~10 years ago), I had a choice of using the official API, or the debug API. The official API was rigid, and fast. The debug API was very flexible, and inconsistently slow. I implemented using the debug API first, with the expectation that I’d move to the offical API the next day. But it always worked just-well-enough that it never became a priority.
I don’t know if the official API would have the same error in the data that is so prevalent in the debug API, but it would have a significantly higher frequency. Even if the same percentage of time was error, it would give me more samples for my data cleaning algorithm to establish confidence that the data was clean again when it had become clean. This would enable much tighter control of the more aggressive algorithms like the overshoot protection.
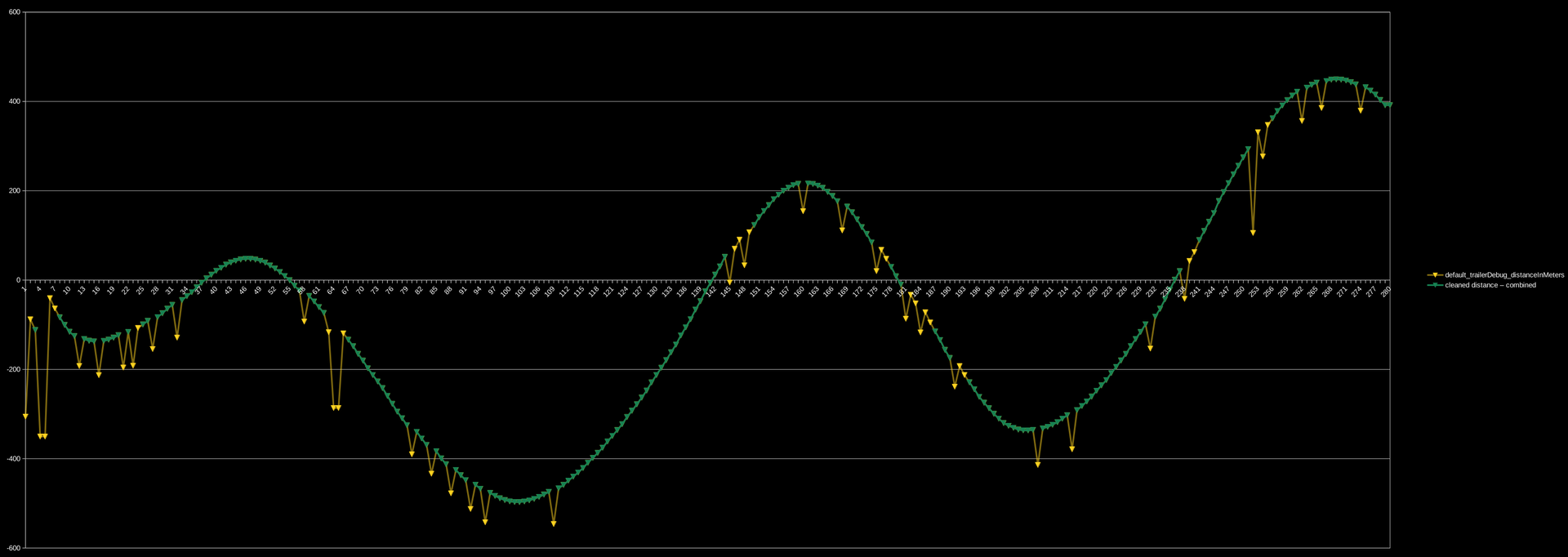
Above: A screenshot of the raw data (yellow) vs the prototyped cleaned data (green).
The projects
Wrapping up
There’s so much more to talk about. So I’ll likely do a follow-up post when time allows.