
FunnyHacks recently underwent an overhaul from top to bottom. I covered the front-end stuff on FunnyHacks.com, and that was the right place for the post introducing the changes. But since RandomKSandom is where I’m going to be posting future content like this, this seemed like the right place to continue. This post is an SRE’s confession about what happened, and why it needed to be replaced.
While most of my posts are definitely aimed at a techy audience, this one is a bit more general.
- Site look and logic.
- An SRE’s confession P(1/1). - You are here.
- An SRE’s confession P(2/2).
- Under the hood.
- Why I chose the tooling that I did.
- Accessibility.
Let’s start by seeing where FunnyHacks came from.
A little beginning
I’ve been trying to electrocute myself by building silly things since the mid 80s. For now, let’s skip to just before I started using the FunnyHacks name.
I had just recently travelled around the world and had built up a bit of an audience on my [now defunct] blog for it. So I posted a post about running a phone off AAs. This wasn’t really the place, so I created a blogspot account and moved the post there. This was a great start, but it was really limiting for what I wanted to do, so I set about creating a website for it.
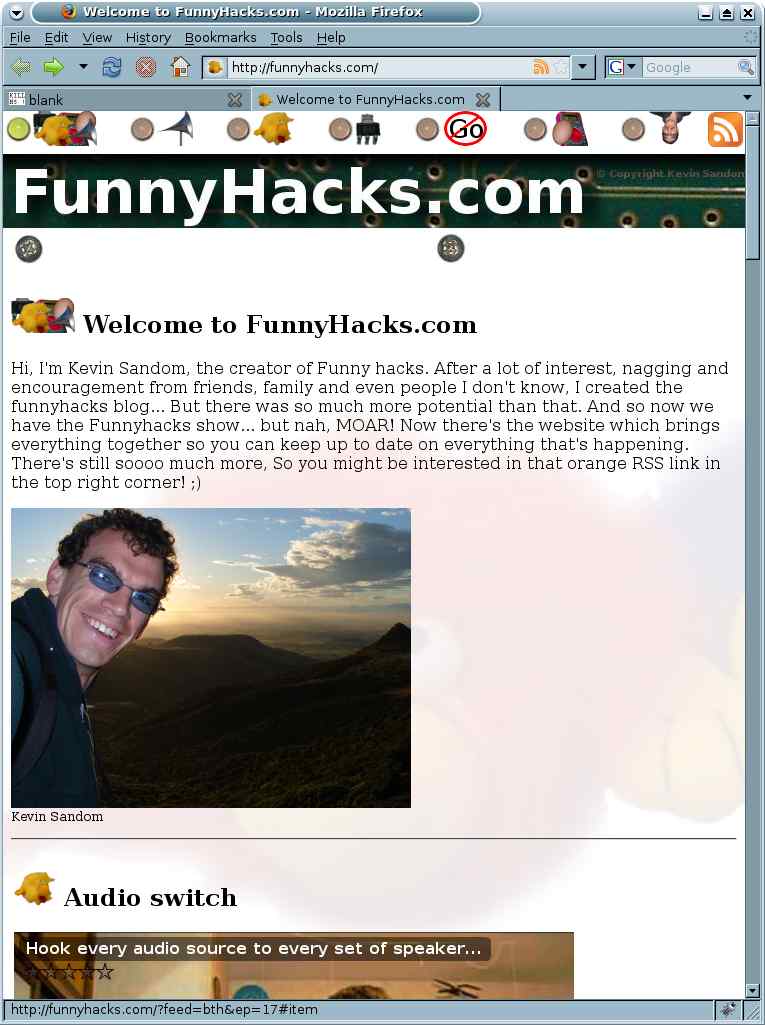
Above: A screenshot of the first site.
Posts for that were stored as a PHP file with a predicatable name like 11fh-d.php in a directory:
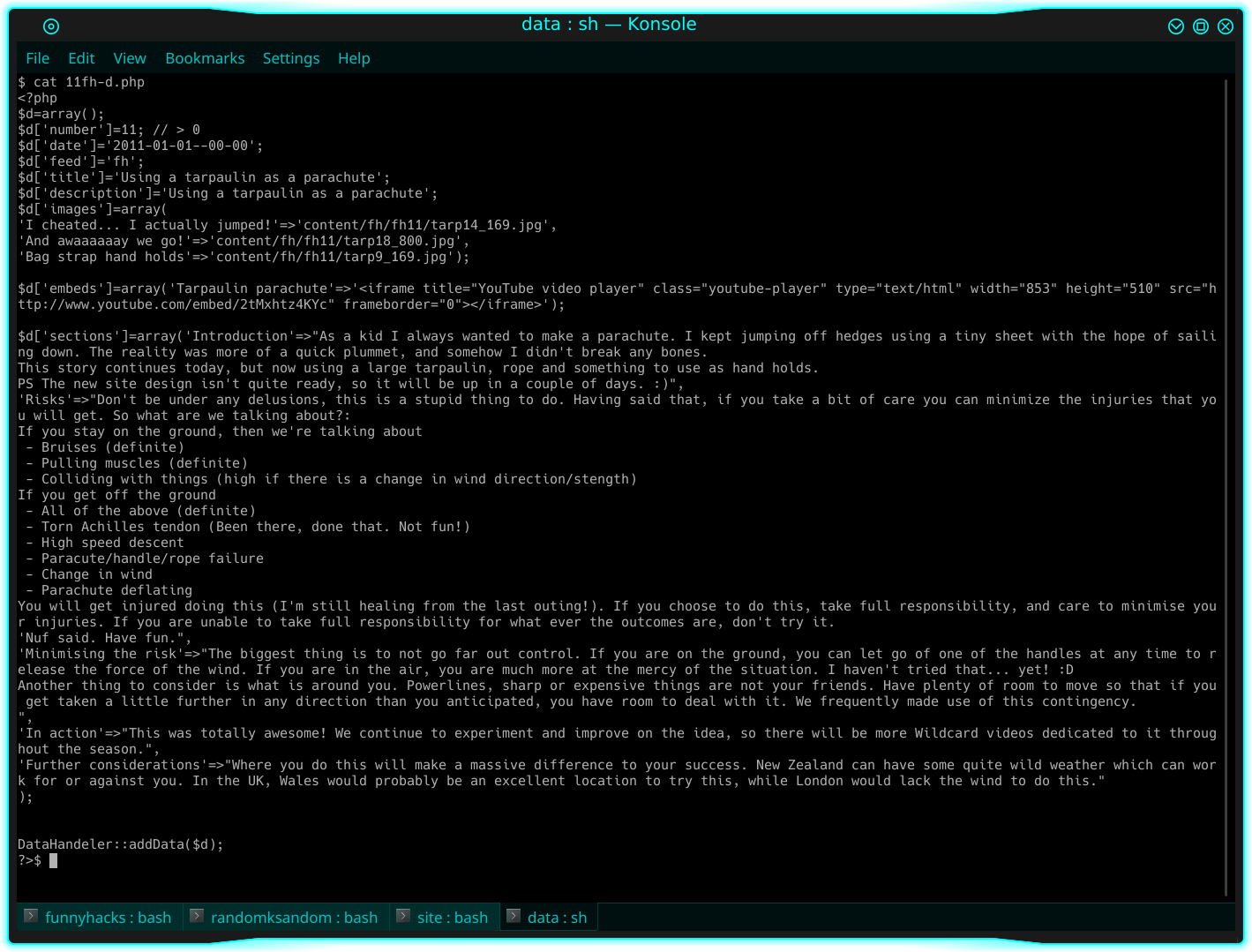
Above: A screenshot of the contents of a post on the first site.
Essentially, it was a hard-coded array that would only get loaded when it was relevant to the task at hand. It was a bit cumbersome to write, but it
- worked well.
- had very little that could go wrong other than syntax, which was easy to test.
- and was really fast.
More possibilities
But after a few months, this became more and more restrictive against the things I wanted to be doing. It seemed that I was adding a new data type every time I added a new post. I was starting to spend a fair bit of time developing the site rather than the content.
It was time to build something that was content focussed, and that allowed me to add functionality easily, while getting out of the way when I just wanted to add content.
Luckily, I had recently built a CMS for another project, and owned the code. This made a lot of sense because I could use an HTML WYSIWYG editor to do the heavy lifting for the content, and the CMS to do the heavy lifting for managing the content, and routing it correctly. But I could also jump into PHP to do completely custom stuff like generating the youtube embed code directly from a user(me) pasted youtube link. That way, every time youtube changed their embed code, or I changed the formatting of my pages, it would be changed everywhere rather than on a page-by-page basis. And I only needed to grab the URL rather clicking through to the share code. - This is kind of an expected feature these days. But back then, it was still fairly novel.
I also used memcached to massively increase performance on low end (cheap!) hardware.
With all of this, I also did a site redesign, that looked like this:
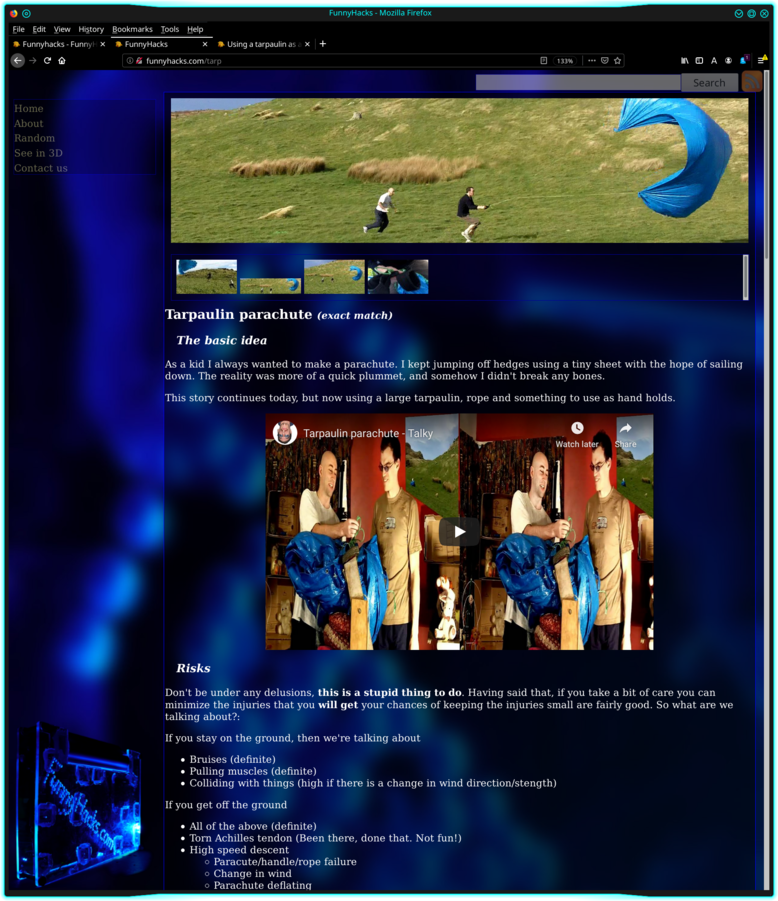
Above: A screenshot of the second site.
I love this design. But it needed to change. If you haven’t already, you can read about why in the FunnyHacks “Site look and logic” post, and the up-coming accessibilty post.
I also started to play with a few things. Notably
- tags.
- related items.
- search.
- simple URLs.
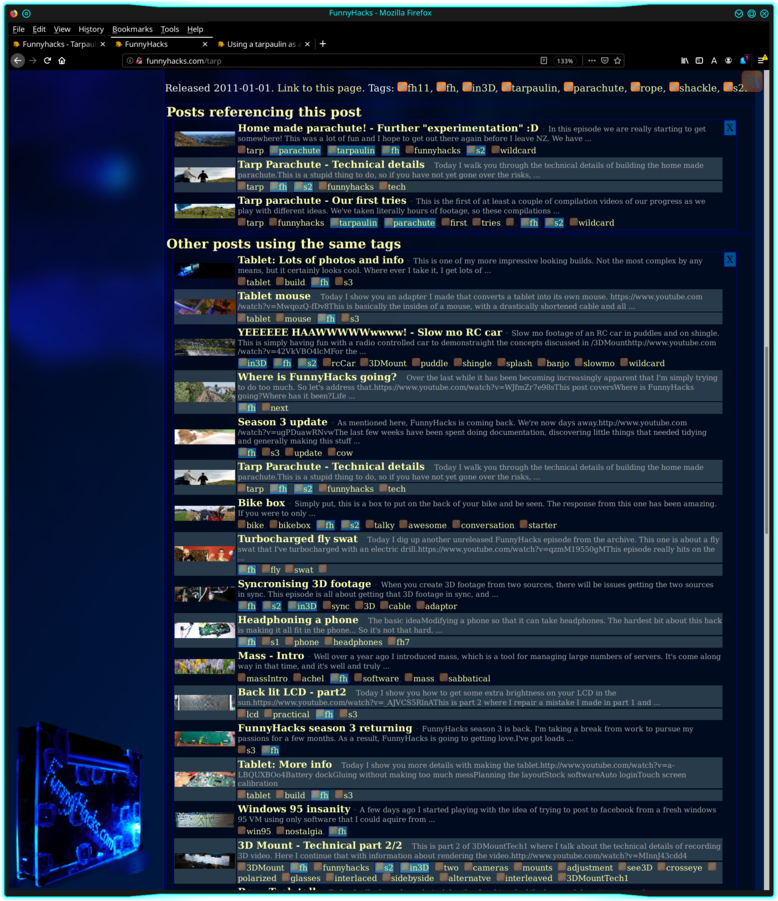
Above: A screenshot of the related items on the second site.
Tags
Every tag could now be clicked on to view all posts with that tag. Every tag also had its own RSS feed that a user could subscribe to. This meant that if you were particularly fascinated with one specific thing I was doing. Eg 3D), you could get notified about just that, and ignore everything else.
Even though RSS doesn’t have the user-base it once had, this was still one of my MVP features for the new site.
Related items
Since this was driven by SQL, it was very easy for me to search the content in interesting ways and display related items accordinly. One of the more interesting aspects to this was that I had different searches for different contexts, so that related items would always feel more relevant to what you were doing on the site.
To subtly show this off, I have a few things like highlighting tags based on why they were selected, and in some contexts, there would be multiple searches provided. The results would be grouped so they could be easily digested.
A much simpler version of this is present on the new site. But I have plans to re-introduce the full concept in the near future.
Search
With all of this different context sitting right there, search was actually quite fun. The best result would be displayed in full, and the remaining items would be displayed as related items at the bottom of the page. Once again I played with different context based possibilities and grouped them at the bottom.
At the time of writing, I’m providing equivalent-ish functionality via google on the new site.
Simple URLs
Traditionally, most sites have a “/this” goes to “that” approach to URLs. With this version of the site, every /something request, was a search for “something”. The result of this was that you didn’t need to get the URL exactly right. In fact, you could put in completely different words, and it would almost always give you what you wanted.
At the time of writing this is provided in the most basic way on the new site, but I have plans to re-introduce it in full. Watch this space :)
A new home
In 2012, I moved it to my own server. Until that point, I had been sharing a server with a friend. But I wanted to experiment with different ideas, yet I didn’t want to be the noisy neighbour that could impact live traffic and affect his business. So it was well and truly time for me to pay for my own server.
I moved to Ubuntu server 12.04 on a t1.micro. This thing ran beauuuuuutifully from the first day until the end!
“Just a hobby”
There was so much I wanted to do to the site, like on-the-fly integration with colouredWeb to both demonstrate, and provide people with custom global stylesheets generated on-the-fly to their preferences, and to provide people with a mechanism for automatic updates as the stylesheets improve. But ultimately this is all stuff I was working on in my spare time, for which there was(is) not a lot. I had to prioritise, so the site took a back seat.
There were a few basics that I did from the start, for example disallowing password based authentication on SSH. And at some point, I noticed that I could do the input field data sanitisation better, so I fixed that pretty quickly. And then that theme continued: When I’d spot a problem, I’d do something to fix it. But really, after a few improvements in the beginning. Everything just chugged along beautifully with it very rarely needing attention.
Summing up so far
So far we’ve covered where the site came from, how it grew, and where it sat in my priorities.
In part 2 I’ll cover how the scope and requirements changed, why that matters, and what I did about it.